Python入門 〜pandasでデータ分析編〜¶
TL;DR¶
Pandasとは¶
Kaggleとは¶
今回はKaggleのチュートリアルに沿うことでデータ分析入門を目指す
データ分析のプロセス¶
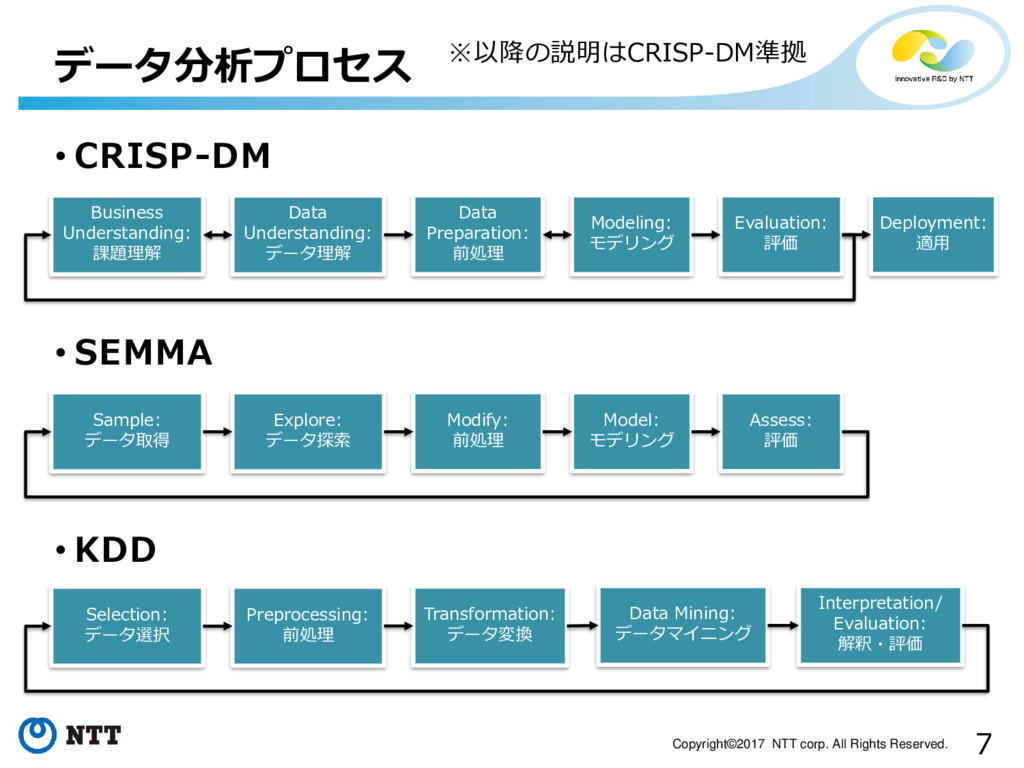
Process
- データの加工
- 予測モデルの作成・学習
- 予測モデルの評価
の3段階で考えるのはどうでしょう(?)
本編¶
1. データの加工¶
データのロード¶
※A free interactive Machine Learning tutorial in Pythonにインタラクティブなチュートリアルがあります
In [1]:
import pandas as pd
In [2]:
train_url = "http://s3.amazonaws.com/assets.datacamp.com/course/Kaggle/train.csv"
train_df = pd.read_csv(train_url)
train_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
- PassengerID: 乗客ID
- Survived: 生存結果 (1: 生存, 0: 死亡)
- Pclass: 客室の等級
- Name: 乗客の名前
- Sex: 性別
- Age: 年齢
- SibSp: 乗船している兄弟,配偶者の数
- Parch: 乗船している両親,子供の数
- Ticket: チケット番号
- Fare: 乗船料金
- Cabin: 部屋番号
- Embarked: 乗船した港 Cherbourg,Queenstown,Southamptonの3種類
In [3]:
train_df
Out[3]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
| 8 | 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S |
| 9 | 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C |
| 10 | 11 | 1 | 3 | Sandstrom, Miss. Marguerite Rut | female | 4.0 | 1 | 1 | PP 9549 | 16.7000 | G6 | S |
| 11 | 12 | 1 | 1 | Bonnell, Miss. Elizabeth | female | 58.0 | 0 | 0 | 113783 | 26.5500 | C103 | S |
| 12 | 13 | 0 | 3 | Saundercock, Mr. William Henry | male | 20.0 | 0 | 0 | A/5. 2151 | 8.0500 | NaN | S |
| 13 | 14 | 0 | 3 | Andersson, Mr. Anders Johan | male | 39.0 | 1 | 5 | 347082 | 31.2750 | NaN | S |
| 14 | 15 | 0 | 3 | Vestrom, Miss. Hulda Amanda Adolfina | female | 14.0 | 0 | 0 | 350406 | 7.8542 | NaN | S |
| 15 | 16 | 1 | 2 | Hewlett, Mrs. (Mary D Kingcome) | female | 55.0 | 0 | 0 | 248706 | 16.0000 | NaN | S |
| 16 | 17 | 0 | 3 | Rice, Master. Eugene | male | 2.0 | 4 | 1 | 382652 | 29.1250 | NaN | Q |
| 17 | 18 | 1 | 2 | Williams, Mr. Charles Eugene | male | NaN | 0 | 0 | 244373 | 13.0000 | NaN | S |
| 18 | 19 | 0 | 3 | Vander Planke, Mrs. Julius (Emelia Maria Vande... | female | 31.0 | 1 | 0 | 345763 | 18.0000 | NaN | S |
| 19 | 20 | 1 | 3 | Masselmani, Mrs. Fatima | female | NaN | 0 | 0 | 2649 | 7.2250 | NaN | C |
| 20 | 21 | 0 | 2 | Fynney, Mr. Joseph J | male | 35.0 | 0 | 0 | 239865 | 26.0000 | NaN | S |
| 21 | 22 | 1 | 2 | Beesley, Mr. Lawrence | male | 34.0 | 0 | 0 | 248698 | 13.0000 | D56 | S |
| 22 | 23 | 1 | 3 | McGowan, Miss. Anna "Annie" | female | 15.0 | 0 | 0 | 330923 | 8.0292 | NaN | Q |
| 23 | 24 | 1 | 1 | Sloper, Mr. William Thompson | male | 28.0 | 0 | 0 | 113788 | 35.5000 | A6 | S |
| 24 | 25 | 0 | 3 | Palsson, Miss. Torborg Danira | female | 8.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
| 25 | 26 | 1 | 3 | Asplund, Mrs. Carl Oscar (Selma Augusta Emilia... | female | 38.0 | 1 | 5 | 347077 | 31.3875 | NaN | S |
| 26 | 27 | 0 | 3 | Emir, Mr. Farred Chehab | male | NaN | 0 | 0 | 2631 | 7.2250 | NaN | C |
| 27 | 28 | 0 | 1 | Fortune, Mr. Charles Alexander | male | 19.0 | 3 | 2 | 19950 | 263.0000 | C23 C25 C27 | S |
| 28 | 29 | 1 | 3 | O'Dwyer, Miss. Ellen "Nellie" | female | NaN | 0 | 0 | 330959 | 7.8792 | NaN | Q |
| 29 | 30 | 0 | 3 | Todoroff, Mr. Lalio | male | NaN | 0 | 0 | 349216 | 7.8958 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 861 | 862 | 0 | 2 | Giles, Mr. Frederick Edward | male | 21.0 | 1 | 0 | 28134 | 11.5000 | NaN | S |
| 862 | 863 | 1 | 1 | Swift, Mrs. Frederick Joel (Margaret Welles Ba... | female | 48.0 | 0 | 0 | 17466 | 25.9292 | D17 | S |
| 863 | 864 | 0 | 3 | Sage, Miss. Dorothy Edith "Dolly" | female | NaN | 8 | 2 | CA. 2343 | 69.5500 | NaN | S |
| 864 | 865 | 0 | 2 | Gill, Mr. John William | male | 24.0 | 0 | 0 | 233866 | 13.0000 | NaN | S |
| 865 | 866 | 1 | 2 | Bystrom, Mrs. (Karolina) | female | 42.0 | 0 | 0 | 236852 | 13.0000 | NaN | S |
| 866 | 867 | 1 | 2 | Duran y More, Miss. Asuncion | female | 27.0 | 1 | 0 | SC/PARIS 2149 | 13.8583 | NaN | C |
| 867 | 868 | 0 | 1 | Roebling, Mr. Washington Augustus II | male | 31.0 | 0 | 0 | PC 17590 | 50.4958 | A24 | S |
| 868 | 869 | 0 | 3 | van Melkebeke, Mr. Philemon | male | NaN | 0 | 0 | 345777 | 9.5000 | NaN | S |
| 869 | 870 | 1 | 3 | Johnson, Master. Harold Theodor | male | 4.0 | 1 | 1 | 347742 | 11.1333 | NaN | S |
| 870 | 871 | 0 | 3 | Balkic, Mr. Cerin | male | 26.0 | 0 | 0 | 349248 | 7.8958 | NaN | S |
| 871 | 872 | 1 | 1 | Beckwith, Mrs. Richard Leonard (Sallie Monypeny) | female | 47.0 | 1 | 1 | 11751 | 52.5542 | D35 | S |
| 872 | 873 | 0 | 1 | Carlsson, Mr. Frans Olof | male | 33.0 | 0 | 0 | 695 | 5.0000 | B51 B53 B55 | S |
| 873 | 874 | 0 | 3 | Vander Cruyssen, Mr. Victor | male | 47.0 | 0 | 0 | 345765 | 9.0000 | NaN | S |
| 874 | 875 | 1 | 2 | Abelson, Mrs. Samuel (Hannah Wizosky) | female | 28.0 | 1 | 0 | P/PP 3381 | 24.0000 | NaN | C |
| 875 | 876 | 1 | 3 | Najib, Miss. Adele Kiamie "Jane" | female | 15.0 | 0 | 0 | 2667 | 7.2250 | NaN | C |
| 876 | 877 | 0 | 3 | Gustafsson, Mr. Alfred Ossian | male | 20.0 | 0 | 0 | 7534 | 9.8458 | NaN | S |
| 877 | 878 | 0 | 3 | Petroff, Mr. Nedelio | male | 19.0 | 0 | 0 | 349212 | 7.8958 | NaN | S |
| 878 | 879 | 0 | 3 | Laleff, Mr. Kristo | male | NaN | 0 | 0 | 349217 | 7.8958 | NaN | S |
| 879 | 880 | 1 | 1 | Potter, Mrs. Thomas Jr (Lily Alexenia Wilson) | female | 56.0 | 0 | 1 | 11767 | 83.1583 | C50 | C |
| 880 | 881 | 1 | 2 | Shelley, Mrs. William (Imanita Parrish Hall) | female | 25.0 | 0 | 1 | 230433 | 26.0000 | NaN | S |
| 881 | 882 | 0 | 3 | Markun, Mr. Johann | male | 33.0 | 0 | 0 | 349257 | 7.8958 | NaN | S |
| 882 | 883 | 0 | 3 | Dahlberg, Miss. Gerda Ulrika | female | 22.0 | 0 | 0 | 7552 | 10.5167 | NaN | S |
| 883 | 884 | 0 | 2 | Banfield, Mr. Frederick James | male | 28.0 | 0 | 0 | C.A./SOTON 34068 | 10.5000 | NaN | S |
| 884 | 885 | 0 | 3 | Sutehall, Mr. Henry Jr | male | 25.0 | 0 | 0 | SOTON/OQ 392076 | 7.0500 | NaN | S |
| 885 | 886 | 0 | 3 | Rice, Mrs. William (Margaret Norton) | female | 39.0 | 0 | 5 | 382652 | 29.1250 | NaN | Q |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
891 rows × 12 columns
量的データ¶
In [4]:
# train_df.describe()
# train_df.describe(percentiles=[.61, .62])
# train_df.describe(percentiles=[.75, .8])
# train_df.describe(percentiles=[.68, .69])
train_df.describe(percentiles=[.1, .2, .3, .4, .5, .6, .7, .8, .9, .99])
Out[4]:
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 10% | 90.000000 | 0.000000 | 1.000000 | 14.000000 | 0.000000 | 0.000000 | 7.550000 |
| 20% | 179.000000 | 0.000000 | 1.000000 | 19.000000 | 0.000000 | 0.000000 | 7.854200 |
| 30% | 268.000000 | 0.000000 | 2.000000 | 22.000000 | 0.000000 | 0.000000 | 8.050000 |
| 40% | 357.000000 | 0.000000 | 2.000000 | 25.000000 | 0.000000 | 0.000000 | 10.500000 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 60% | 535.000000 | 0.000000 | 3.000000 | 31.800000 | 0.000000 | 0.000000 | 21.679200 |
| 70% | 624.000000 | 1.000000 | 3.000000 | 36.000000 | 1.000000 | 0.000000 | 27.000000 |
| 80% | 713.000000 | 1.000000 | 3.000000 | 41.000000 | 1.000000 | 1.000000 | 39.687500 |
| 90% | 802.000000 | 1.000000 | 3.000000 | 50.000000 | 1.000000 | 2.000000 | 77.958300 |
| 99% | 882.100000 | 1.000000 | 3.000000 | 65.870000 | 5.000000 | 4.000000 | 249.006220 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
describe()で簡単な統計量(基本・要約・記述統計量)を一覧できる
- 891人中生き残った人のデータは38%ほど
- 親や子供と共に乗っていない人が75%くらい
- 兄弟や配偶者と共に乗っていない人が70%くらい
- $512も払っている人は1%未満
- 65歳以上の人も1%未満
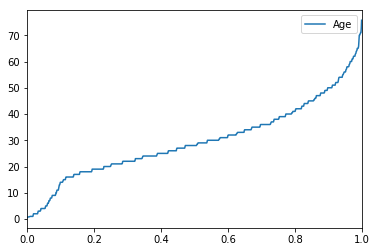
可視化¶
パーセンタイルを折れ線グラフで見てみる
In [5]:
import matplotlib.pyplot as plt
import seaborn as sns
% matplotlib inline
In [6]:
train_df.quantile([.1, .2, .3, .4, .5, .6, .7, .8, .9])
Out[6]:
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| 0.1 | 90.0 | 0.0 | 1.0 | 14.0 | 0.0 | 0.0 | 7.5500 |
| 0.2 | 179.0 | 0.0 | 1.0 | 19.0 | 0.0 | 0.0 | 7.8542 |
| 0.3 | 268.0 | 0.0 | 2.0 | 22.0 | 0.0 | 0.0 | 8.0500 |
| 0.4 | 357.0 | 0.0 | 2.0 | 25.0 | 0.0 | 0.0 | 10.5000 |
| 0.5 | 446.0 | 0.0 | 3.0 | 28.0 | 0.0 | 0.0 | 14.4542 |
| 0.6 | 535.0 | 0.0 | 3.0 | 31.8 | 0.0 | 0.0 | 21.6792 |
| 0.7 | 624.0 | 1.0 | 3.0 | 36.0 | 1.0 | 0.0 | 27.0000 |
| 0.8 | 713.0 | 1.0 | 3.0 | 41.0 | 1.0 | 1.0 | 39.6875 |
| 0.9 | 802.0 | 1.0 | 3.0 | 50.0 | 1.0 | 2.0 | 77.9583 |
In [7]:
import numpy as np
np.arange(0, 1, .1)
Out[7]:
array([ 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
In [8]:
train_df.quantile(np.arange(0, 1, .001)).plot(y="Age")
Out[8]:
<matplotlib.axes._subplots.AxesSubplot at 0x10aa3b358>
質的データ¶
In [9]:
train_df.describe(include=[np.object])
Out[9]:
| Name | Sex | Ticket | Cabin | Embarked | |
|---|---|---|---|---|---|
| count | 891 | 891 | 891 | 204 | 889 |
| unique | 891 | 2 | 681 | 147 | 3 |
| top | Blackwell, Mr. Stephen Weart | male | CA. 2343 | G6 | S |
| freq | 1 | 577 | 7 | 4 | 644 |
- Nameは一意
- 65%が男性
- 客室には複数の人が泊まっていたり,一人が複数の客室を使用していたりする
- 乗船した港は3種類だがほとんどがS
- Ticketは22%も重複している
データ観察からの仮説¶
参考:https://www.kaggle.com/startupsci/titanic-data-science-solutions
補完
- 生死と相関のある年齢は補完したい
- Embarkedも補完したいかもしれない
修正
- 22%も重複しているTicketは分析には不適ではないか
- Cabinは欠損値が多すぎるのでつかえない
- PassengerIdはただの番号
- 名前は生死に無関係では
作成
- ParchとSibSpを使えば家族数が割り出せるのでは
- 名前から敬称を取り出せる
- 年齢の連続値より年齢層として扱う方がいいかもしれない
- 料金も同様に
分類
- 女性は生き残る可能性が高いか
- 子供は生き残る可能性が高いか
- 上位クラスの乗客は生き残る可能性が高いか
相関を見る¶
In [10]:
train_df[0:5]
Out[10]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
In [11]:
print(type(train_df[["Sex"]]))
train_df[["Sex"]]
<class 'pandas.core.frame.DataFrame'>
Out[11]:
| Sex | |
|---|---|
| 0 | male |
| 1 | female |
| 2 | female |
| 3 | female |
| 4 | male |
| 5 | male |
| 6 | male |
| 7 | male |
| 8 | female |
| 9 | female |
| 10 | female |
| 11 | female |
| 12 | male |
| 13 | male |
| 14 | female |
| 15 | female |
| 16 | male |
| 17 | male |
| 18 | female |
| 19 | female |
| 20 | male |
| 21 | male |
| 22 | female |
| 23 | male |
| 24 | female |
| 25 | female |
| 26 | male |
| 27 | male |
| 28 | female |
| 29 | male |
| ... | ... |
| 861 | male |
| 862 | female |
| 863 | female |
| 864 | male |
| 865 | female |
| 866 | female |
| 867 | male |
| 868 | male |
| 869 | male |
| 870 | male |
| 871 | female |
| 872 | male |
| 873 | male |
| 874 | female |
| 875 | female |
| 876 | male |
| 877 | male |
| 878 | male |
| 879 | female |
| 880 | female |
| 881 | male |
| 882 | female |
| 883 | male |
| 884 | male |
| 885 | female |
| 886 | male |
| 887 | female |
| 888 | female |
| 889 | male |
| 890 | male |
891 rows × 1 columns
In [12]:
print(type(train_df["Sex"]))
train_df["Sex"]
<class 'pandas.core.series.Series'>
Out[12]:
0 male
1 female
2 female
3 female
4 male
5 male
6 male
7 male
8 female
9 female
10 female
11 female
12 male
13 male
14 female
15 female
16 male
17 male
18 female
19 female
20 male
21 male
22 female
23 male
24 female
25 female
26 male
27 male
28 female
29 male
...
861 male
862 female
863 female
864 male
865 female
866 female
867 male
868 male
869 male
870 male
871 female
872 male
873 male
874 female
875 female
876 male
877 male
878 male
879 female
880 female
881 male
882 female
883 male
884 male
885 female
886 male
887 female
888 female
889 male
890 male
Name: Sex, Length: 891, dtype: object
In [13]:
train_df["Sex"][train_df["Sex"] == "male"]
Out[13]:
0 male
4 male
5 male
6 male
7 male
12 male
13 male
16 male
17 male
20 male
21 male
23 male
26 male
27 male
29 male
30 male
33 male
34 male
35 male
36 male
37 male
42 male
45 male
46 male
48 male
50 male
51 male
54 male
55 male
57 male
...
840 male
841 male
843 male
844 male
845 male
846 male
847 male
848 male
850 male
851 male
857 male
859 male
860 male
861 male
864 male
867 male
868 male
869 male
870 male
872 male
873 male
876 male
877 male
878 male
881 male
883 male
884 male
886 male
889 male
890 male
Name: Sex, Length: 577, dtype: object
In [14]:
train_df.loc[train_df["Sex"] == "male", "Sex"]
Out[14]:
0 male
4 male
5 male
6 male
7 male
12 male
13 male
16 male
17 male
20 male
21 male
23 male
26 male
27 male
29 male
30 male
33 male
34 male
35 male
36 male
37 male
42 male
45 male
46 male
48 male
50 male
51 male
54 male
55 male
57 male
...
840 male
841 male
843 male
844 male
845 male
846 male
847 male
848 male
850 male
851 male
857 male
859 male
860 male
861 male
864 male
867 male
868 male
869 male
870 male
872 male
873 male
876 male
877 male
878 male
881 male
883 male
884 male
886 male
889 male
890 male
Name: Sex, Length: 577, dtype: object
In [15]:
train_df_select = train_df.copy()
train_df_select.loc[train_df_select["Sex"] == "male", "Sex"] = 0
train_df_select.loc[train_df_select["Sex"] == "female", "Sex"] = 1
train_df_select = train_df_select.astype({"Sex": int})
train_df_select[["Sex"]]
Out[15]:
| Sex | |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 0 |
| 5 | 0 |
| 6 | 0 |
| 7 | 0 |
| 8 | 1 |
| 9 | 1 |
| 10 | 1 |
| 11 | 1 |
| 12 | 0 |
| 13 | 0 |
| 14 | 1 |
| 15 | 1 |
| 16 | 0 |
| 17 | 0 |
| 18 | 1 |
| 19 | 1 |
| 20 | 0 |
| 21 | 0 |
| 22 | 1 |
| 23 | 0 |
| 24 | 1 |
| 25 | 1 |
| 26 | 0 |
| 27 | 0 |
| 28 | 1 |
| 29 | 0 |
| ... | ... |
| 861 | 0 |
| 862 | 1 |
| 863 | 1 |
| 864 | 0 |
| 865 | 1 |
| 866 | 1 |
| 867 | 0 |
| 868 | 0 |
| 869 | 0 |
| 870 | 0 |
| 871 | 1 |
| 872 | 0 |
| 873 | 0 |
| 874 | 1 |
| 875 | 1 |
| 876 | 0 |
| 877 | 0 |
| 878 | 0 |
| 879 | 1 |
| 880 | 1 |
| 881 | 0 |
| 882 | 1 |
| 883 | 0 |
| 884 | 0 |
| 885 | 1 |
| 886 | 0 |
| 887 | 1 |
| 888 | 1 |
| 889 | 0 |
| 890 | 0 |
891 rows × 1 columns
In [16]:
train_df_select.loc[train_df_select["Embarked"] == "S", "Embarked"] = 0
train_df_select.loc[train_df_select["Embarked"] == "C", "Embarked"] = 1
train_df_select.loc[train_df_select["Embarked"] == "Q", "Embarked"] = 2
train_df_select = train_df_select.dropna(subset=["Embarked"])
train_df_select = train_df_select.astype({"Embarked": int})
train_df_select[["Embarked"]]
Out[16]:
| Embarked | |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 0 |
| 3 | 0 |
| 4 | 0 |
| 5 | 2 |
| 6 | 0 |
| 7 | 0 |
| 8 | 0 |
| 9 | 1 |
| 10 | 0 |
| 11 | 0 |
| 12 | 0 |
| 13 | 0 |
| 14 | 0 |
| 15 | 0 |
| 16 | 2 |
| 17 | 0 |
| 18 | 0 |
| 19 | 1 |
| 20 | 0 |
| 21 | 0 |
| 22 | 2 |
| 23 | 0 |
| 24 | 0 |
| 25 | 0 |
| 26 | 1 |
| 27 | 0 |
| 28 | 2 |
| 29 | 0 |
| ... | ... |
| 861 | 0 |
| 862 | 0 |
| 863 | 0 |
| 864 | 0 |
| 865 | 0 |
| 866 | 1 |
| 867 | 0 |
| 868 | 0 |
| 869 | 0 |
| 870 | 0 |
| 871 | 0 |
| 872 | 0 |
| 873 | 0 |
| 874 | 1 |
| 875 | 1 |
| 876 | 0 |
| 877 | 0 |
| 878 | 0 |
| 879 | 1 |
| 880 | 0 |
| 881 | 0 |
| 882 | 0 |
| 883 | 0 |
| 884 | 0 |
| 885 | 2 |
| 886 | 0 |
| 887 | 0 |
| 888 | 0 |
| 889 | 1 |
| 890 | 2 |
889 rows × 1 columns
とりあえずNaNの含まれるレコードを消して,相関を算出できるデータのみを取り出す
In [17]:
train_df_select_drop = train_df_select.dropna()
train_df_select_drop.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 183 entries, 1 to 889
Data columns (total 12 columns):
PassengerId 183 non-null int64
Survived 183 non-null int64
Pclass 183 non-null int64
Name 183 non-null object
Sex 183 non-null int64
Age 183 non-null float64
SibSp 183 non-null int64
Parch 183 non-null int64
Ticket 183 non-null object
Fare 183 non-null float64
Cabin 183 non-null object
Embarked 183 non-null int64
dtypes: float64(2), int64(7), object(3)
memory usage: 18.6+ KB
In [18]:
train_df_select_drop.corr()
Out[18]:
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|---|
| PassengerId | 1.000000 | 0.148495 | -0.089136 | 0.025205 | 0.030933 | -0.083488 | -0.051454 | 0.029740 | -0.054246 |
| Survived | 0.148495 | 1.000000 | -0.034542 | 0.532418 | -0.254085 | 0.106346 | 0.023582 | 0.134241 | 0.083231 |
| Pclass | -0.089136 | -0.034542 | 1.000000 | 0.046181 | -0.306514 | -0.103592 | 0.047496 | -0.315235 | -0.235027 |
| Sex | 0.025205 | 0.532418 | 0.046181 | 1.000000 | -0.184969 | 0.104291 | 0.089581 | 0.130433 | 0.060862 |
| Age | 0.030933 | -0.254085 | -0.306514 | -0.184969 | 1.000000 | -0.156162 | -0.271271 | -0.092424 | 0.088112 |
| SibSp | -0.083488 | 0.106346 | -0.103592 | 0.104291 | -0.156162 | 1.000000 | 0.255346 | 0.286433 | 0.015962 |
| Parch | -0.051454 | 0.023582 | 0.047496 | 0.089581 | -0.271271 | 0.255346 | 1.000000 | 0.389740 | -0.097495 |
| Fare | 0.029740 | 0.134241 | -0.315235 | 0.130433 | -0.092424 | 0.286433 | 0.389740 | 1.000000 | 0.233452 |
| Embarked | -0.054246 | 0.083231 | -0.235027 | 0.060862 | 0.088112 | 0.015962 | -0.097495 | 0.233452 | 1.000000 |
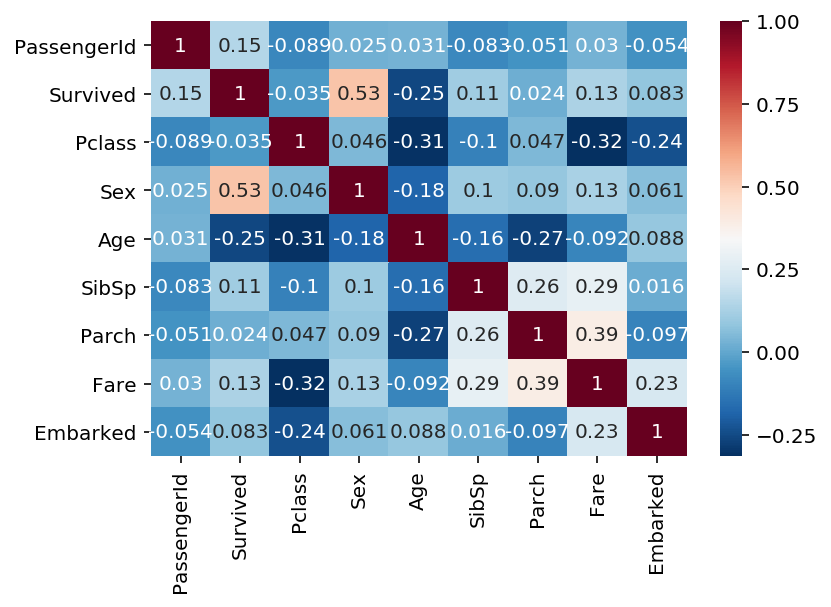
In [19]:
%config InlineBackend.figure_formats = {'png', 'retina'}
sns.heatmap(train_df_select_drop.corr(), annot=True, cmap='RdBu_r')
Out[19]:
<matplotlib.axes._subplots.AxesSubplot at 0x10aa3bc88>
| 尺度 | 例 | 大小比較 | 差 | 比 |
| 名義尺度 | 電話番号 | × | × | × |
| 順序尺度 | 震度 | ○ | × | × |
| 間隔尺度 | 温度(℃) | ○ | ○ | × |
| 比率尺度 | 長さ | ○ | ○ | ○ |
分布を見る¶
In [20]:
sns.pairplot(train_df_select[["Sex", 'Survived']], hue='Survived')
Out[20]:
<seaborn.axisgrid.PairGrid at 0x10ab174a8>
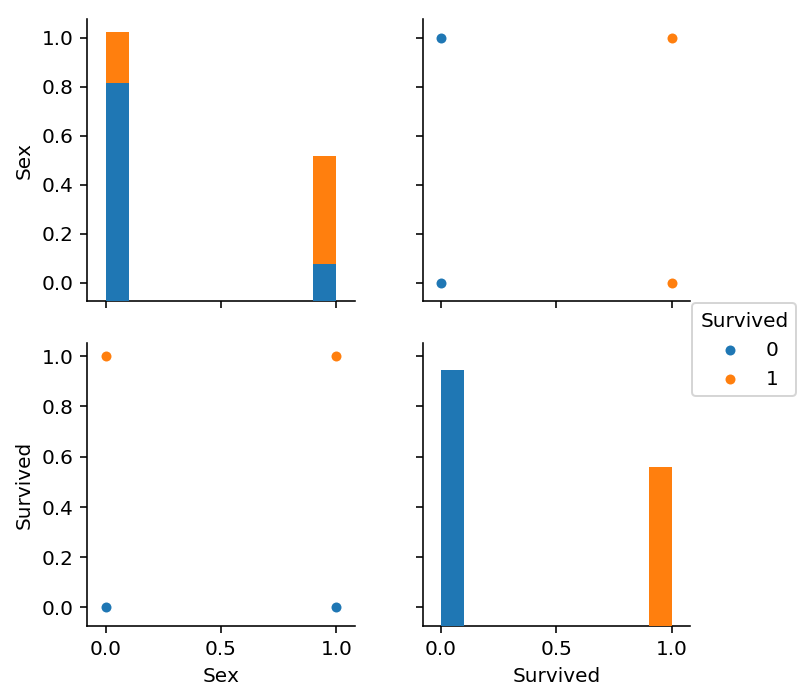
Femaleのほうが生存率が高い
In [21]:
sns.pairplot(train_df_select[["Age", 'Survived']].dropna(), hue='Survived')
Out[21]:
<seaborn.axisgrid.PairGrid at 0x10b8e34e0>
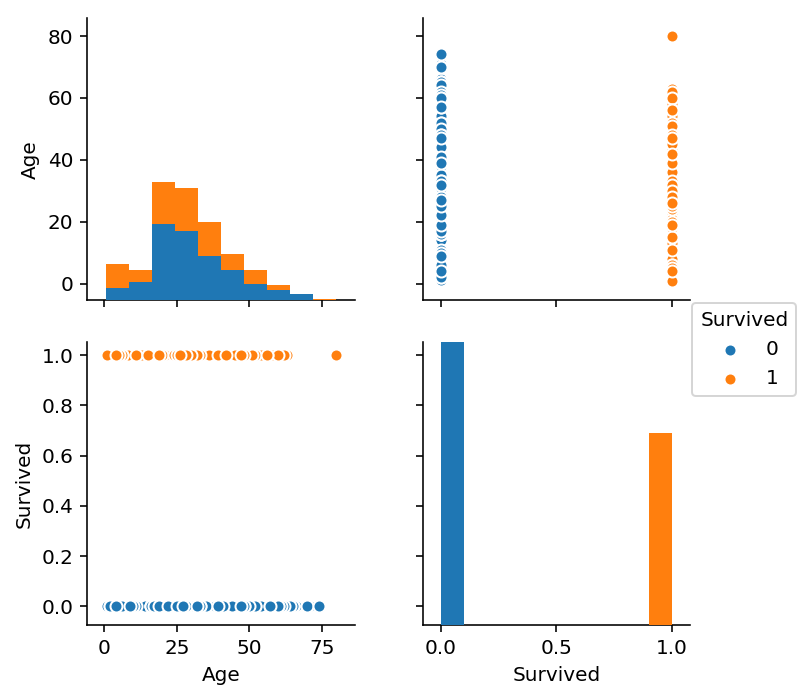
In [22]:
sns.pairplot(train_df_select[["Pclass", 'Survived']], hue='Survived')
Out[22]:
<seaborn.axisgrid.PairGrid at 0x10c3ab2b0>
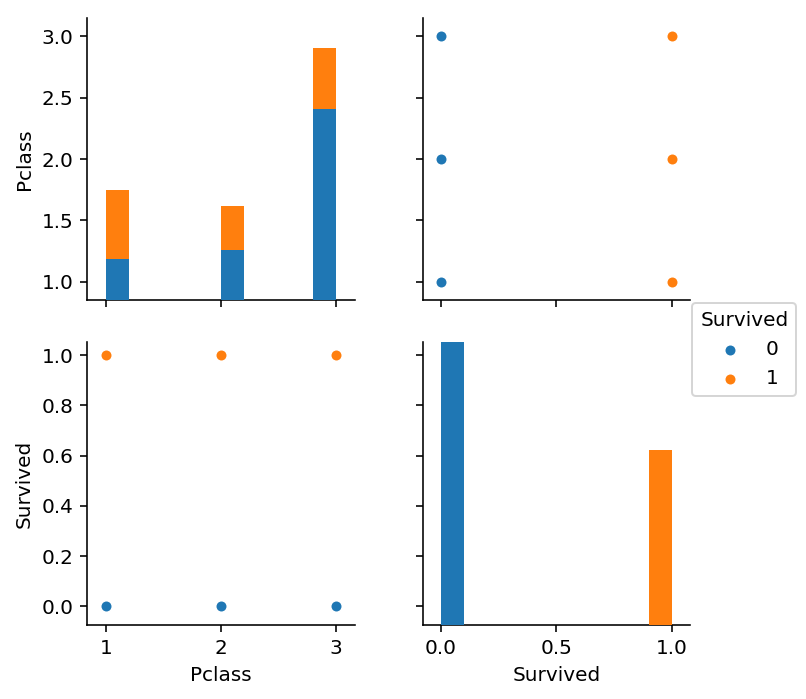
1>2>3等の順で生存率が高い
In [23]:
sns.pairplot(train_df_select[["Fare", 'Survived']], hue='Survived')
Out[23]:
<seaborn.axisgrid.PairGrid at 0x10bcd70f0>
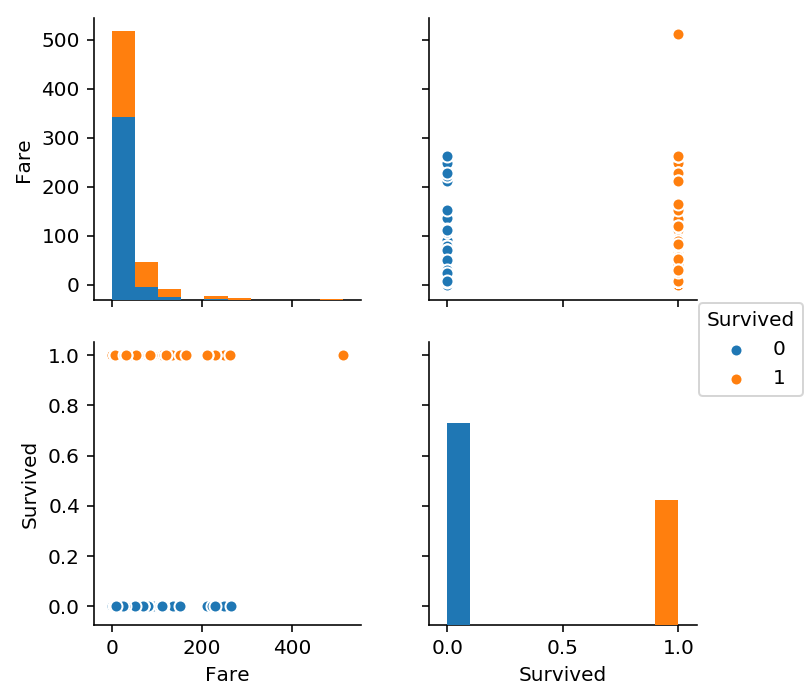
In [24]:
sns.pairplot(train_df_select[["Embarked", 'Survived']], hue='Survived')
Out[24]:
<seaborn.axisgrid.PairGrid at 0x10c70a400>
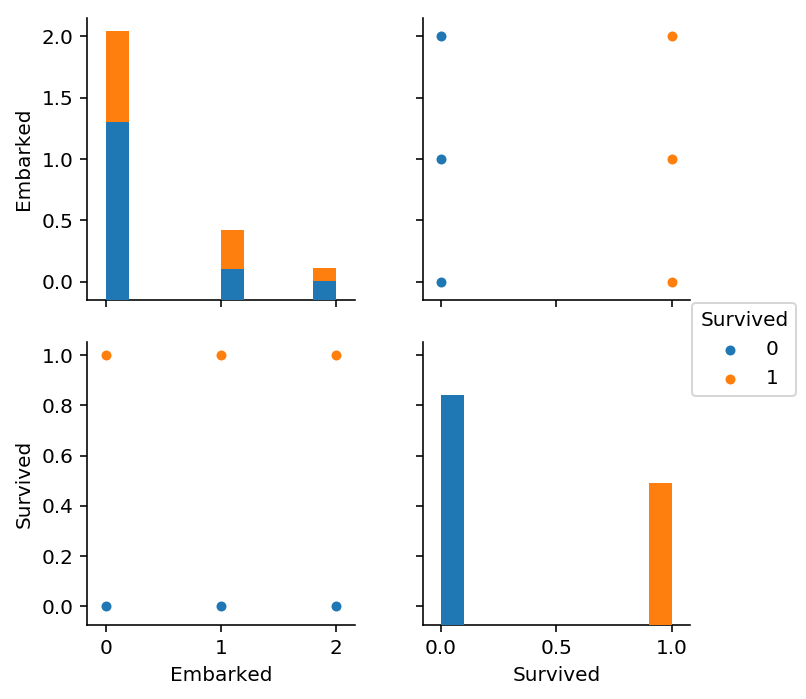
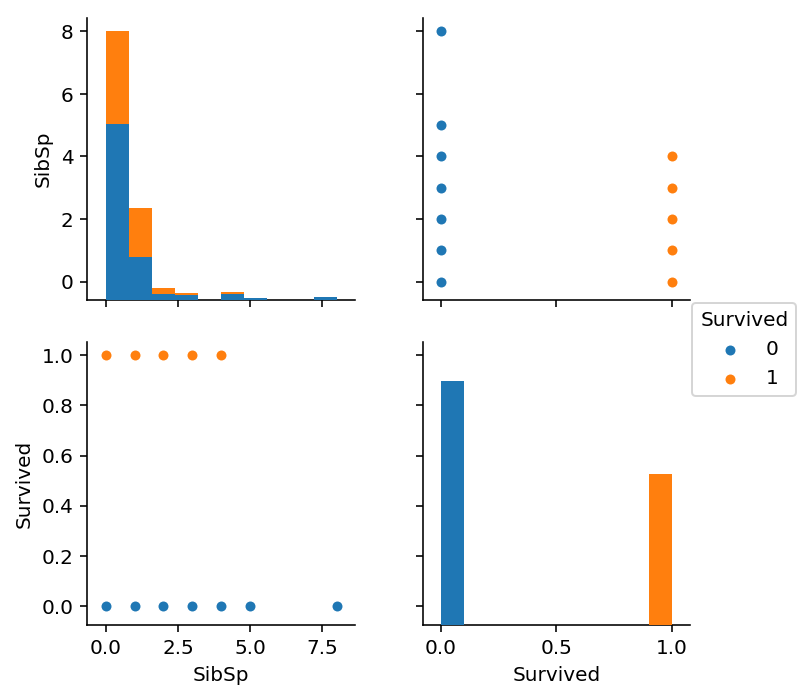
In [25]:
sns.pairplot(train_df_select[["SibSp", 'Survived']], hue='Survived')
Out[25]:
<seaborn.axisgrid.PairGrid at 0x10de8f898>
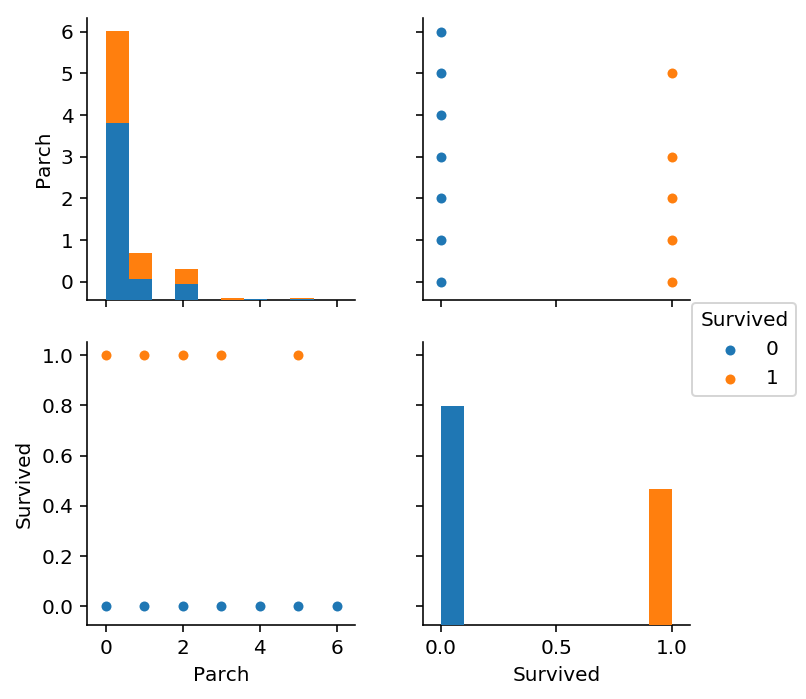
In [26]:
sns.pairplot(train_df_select[["Parch", 'Survived']], hue='Survived')
Out[26]:
<seaborn.axisgrid.PairGrid at 0x10e523ef0>
2.予測モデルの作成・学習¶
In [27]:
train_df = pd.read_csv("http://s3.amazonaws.com/assets.datacamp.com/course/Kaggle/train.csv")
test_df = pd.read_csv("http://s3.amazonaws.com/assets.datacamp.com/course/Kaggle/test.csv")
train_df.shape, test_df.shape
Out[27]:
((891, 12), (418, 11))
データの整理¶

axis
In [28]:
all_df = pd.concat([train_df.drop('Survived', axis=1), test_df], axis=0)
all_df = pd.get_dummies(all_df[["Pclass", "Sex", "Age", "Fare"]])
all_df
Out[28]:
| Pclass | Age | Fare | Sex_female | Sex_male | |
|---|---|---|---|---|---|
| 0 | 3 | 22.0 | 7.2500 | 0 | 1 |
| 1 | 1 | 38.0 | 71.2833 | 1 | 0 |
| 2 | 3 | 26.0 | 7.9250 | 1 | 0 |
| 3 | 1 | 35.0 | 53.1000 | 1 | 0 |
| 4 | 3 | 35.0 | 8.0500 | 0 | 1 |
| 5 | 3 | NaN | 8.4583 | 0 | 1 |
| 6 | 1 | 54.0 | 51.8625 | 0 | 1 |
| 7 | 3 | 2.0 | 21.0750 | 0 | 1 |
| 8 | 3 | 27.0 | 11.1333 | 1 | 0 |
| 9 | 2 | 14.0 | 30.0708 | 1 | 0 |
| 10 | 3 | 4.0 | 16.7000 | 1 | 0 |
| 11 | 1 | 58.0 | 26.5500 | 1 | 0 |
| 12 | 3 | 20.0 | 8.0500 | 0 | 1 |
| 13 | 3 | 39.0 | 31.2750 | 0 | 1 |
| 14 | 3 | 14.0 | 7.8542 | 1 | 0 |
| 15 | 2 | 55.0 | 16.0000 | 1 | 0 |
| 16 | 3 | 2.0 | 29.1250 | 0 | 1 |
| 17 | 2 | NaN | 13.0000 | 0 | 1 |
| 18 | 3 | 31.0 | 18.0000 | 1 | 0 |
| 19 | 3 | NaN | 7.2250 | 1 | 0 |
| 20 | 2 | 35.0 | 26.0000 | 0 | 1 |
| 21 | 2 | 34.0 | 13.0000 | 0 | 1 |
| 22 | 3 | 15.0 | 8.0292 | 1 | 0 |
| 23 | 1 | 28.0 | 35.5000 | 0 | 1 |
| 24 | 3 | 8.0 | 21.0750 | 1 | 0 |
| 25 | 3 | 38.0 | 31.3875 | 1 | 0 |
| 26 | 3 | NaN | 7.2250 | 0 | 1 |
| 27 | 1 | 19.0 | 263.0000 | 0 | 1 |
| 28 | 3 | NaN | 7.8792 | 1 | 0 |
| 29 | 3 | NaN | 7.8958 | 0 | 1 |
| ... | ... | ... | ... | ... | ... |
| 388 | 3 | 21.0 | 7.7500 | 0 | 1 |
| 389 | 3 | 6.0 | 21.0750 | 0 | 1 |
| 390 | 1 | 23.0 | 93.5000 | 0 | 1 |
| 391 | 1 | 51.0 | 39.4000 | 1 | 0 |
| 392 | 3 | 13.0 | 20.2500 | 0 | 1 |
| 393 | 2 | 47.0 | 10.5000 | 0 | 1 |
| 394 | 3 | 29.0 | 22.0250 | 0 | 1 |
| 395 | 1 | 18.0 | 60.0000 | 1 | 0 |
| 396 | 3 | 24.0 | 7.2500 | 0 | 1 |
| 397 | 1 | 48.0 | 79.2000 | 1 | 0 |
| 398 | 3 | 22.0 | 7.7750 | 0 | 1 |
| 399 | 3 | 31.0 | 7.7333 | 0 | 1 |
| 400 | 1 | 30.0 | 164.8667 | 1 | 0 |
| 401 | 2 | 38.0 | 21.0000 | 0 | 1 |
| 402 | 1 | 22.0 | 59.4000 | 1 | 0 |
| 403 | 1 | 17.0 | 47.1000 | 0 | 1 |
| 404 | 1 | 43.0 | 27.7208 | 0 | 1 |
| 405 | 2 | 20.0 | 13.8625 | 0 | 1 |
| 406 | 2 | 23.0 | 10.5000 | 0 | 1 |
| 407 | 1 | 50.0 | 211.5000 | 0 | 1 |
| 408 | 3 | NaN | 7.7208 | 1 | 0 |
| 409 | 3 | 3.0 | 13.7750 | 1 | 0 |
| 410 | 3 | NaN | 7.7500 | 1 | 0 |
| 411 | 1 | 37.0 | 90.0000 | 1 | 0 |
| 412 | 3 | 28.0 | 7.7750 | 1 | 0 |
| 413 | 3 | NaN | 8.0500 | 0 | 1 |
| 414 | 1 | 39.0 | 108.9000 | 1 | 0 |
| 415 | 3 | 38.5 | 7.2500 | 0 | 1 |
| 416 | 3 | NaN | 8.0500 | 0 | 1 |
| 417 | 3 | NaN | 22.3583 | 0 | 1 |
1309 rows × 5 columns
groupby(集約関数)という便利機能
In [29]:
all_df.groupby(["Pclass"]).mean()
Out[29]:
| Age | Fare | Sex_female | Sex_male | |
|---|---|---|---|---|
| Pclass | ||||
| 1 | 39.159930 | 87.508992 | 0.445820 | 0.554180 |
| 2 | 29.506705 | 21.179196 | 0.382671 | 0.617329 |
| 3 | 24.816367 | 13.302889 | 0.304654 | 0.695346 |
groupbyで欠損値の傾向を確認する
In [30]:
missing = all_df.copy()
missing = missing.isnull()
pd.DataFrame(missing.groupby(missing.columns.tolist()).size())
Out[30]:
| 0 | |||||
|---|---|---|---|---|---|
| Pclass | Age | Fare | Sex_female | Sex_male | |
| False | False | False | False | False | 1045 |
| True | False | False | 1 | ||
| True | False | False | False | 263 |
| リストワイズ法 | 欠損レコードを除去 |
| ペアワイズ法 | 相関係数など2変数を用いて計算を行う際に、 対象の変数が欠損している場合に計算対象から除外 |
| 平均代入法 | 欠損を持つ変数の平均値を補完 |
| 回帰代入法 | 欠損を持つ変数の値を回帰式をもとに補完 |
確率的回帰代入法,完全情報最尤推定法,多重代入法などなど
In [31]:
all_df = all_df.fillna(all_df.median())
all_df
Out[31]:
| Pclass | Age | Fare | Sex_female | Sex_male | |
|---|---|---|---|---|---|
| 0 | 3 | 22.0 | 7.2500 | 0 | 1 |
| 1 | 1 | 38.0 | 71.2833 | 1 | 0 |
| 2 | 3 | 26.0 | 7.9250 | 1 | 0 |
| 3 | 1 | 35.0 | 53.1000 | 1 | 0 |
| 4 | 3 | 35.0 | 8.0500 | 0 | 1 |
| 5 | 3 | 28.0 | 8.4583 | 0 | 1 |
| 6 | 1 | 54.0 | 51.8625 | 0 | 1 |
| 7 | 3 | 2.0 | 21.0750 | 0 | 1 |
| 8 | 3 | 27.0 | 11.1333 | 1 | 0 |
| 9 | 2 | 14.0 | 30.0708 | 1 | 0 |
| 10 | 3 | 4.0 | 16.7000 | 1 | 0 |
| 11 | 1 | 58.0 | 26.5500 | 1 | 0 |
| 12 | 3 | 20.0 | 8.0500 | 0 | 1 |
| 13 | 3 | 39.0 | 31.2750 | 0 | 1 |
| 14 | 3 | 14.0 | 7.8542 | 1 | 0 |
| 15 | 2 | 55.0 | 16.0000 | 1 | 0 |
| 16 | 3 | 2.0 | 29.1250 | 0 | 1 |
| 17 | 2 | 28.0 | 13.0000 | 0 | 1 |
| 18 | 3 | 31.0 | 18.0000 | 1 | 0 |
| 19 | 3 | 28.0 | 7.2250 | 1 | 0 |
| 20 | 2 | 35.0 | 26.0000 | 0 | 1 |
| 21 | 2 | 34.0 | 13.0000 | 0 | 1 |
| 22 | 3 | 15.0 | 8.0292 | 1 | 0 |
| 23 | 1 | 28.0 | 35.5000 | 0 | 1 |
| 24 | 3 | 8.0 | 21.0750 | 1 | 0 |
| 25 | 3 | 38.0 | 31.3875 | 1 | 0 |
| 26 | 3 | 28.0 | 7.2250 | 0 | 1 |
| 27 | 1 | 19.0 | 263.0000 | 0 | 1 |
| 28 | 3 | 28.0 | 7.8792 | 1 | 0 |
| 29 | 3 | 28.0 | 7.8958 | 0 | 1 |
| ... | ... | ... | ... | ... | ... |
| 388 | 3 | 21.0 | 7.7500 | 0 | 1 |
| 389 | 3 | 6.0 | 21.0750 | 0 | 1 |
| 390 | 1 | 23.0 | 93.5000 | 0 | 1 |
| 391 | 1 | 51.0 | 39.4000 | 1 | 0 |
| 392 | 3 | 13.0 | 20.2500 | 0 | 1 |
| 393 | 2 | 47.0 | 10.5000 | 0 | 1 |
| 394 | 3 | 29.0 | 22.0250 | 0 | 1 |
| 395 | 1 | 18.0 | 60.0000 | 1 | 0 |
| 396 | 3 | 24.0 | 7.2500 | 0 | 1 |
| 397 | 1 | 48.0 | 79.2000 | 1 | 0 |
| 398 | 3 | 22.0 | 7.7750 | 0 | 1 |
| 399 | 3 | 31.0 | 7.7333 | 0 | 1 |
| 400 | 1 | 30.0 | 164.8667 | 1 | 0 |
| 401 | 2 | 38.0 | 21.0000 | 0 | 1 |
| 402 | 1 | 22.0 | 59.4000 | 1 | 0 |
| 403 | 1 | 17.0 | 47.1000 | 0 | 1 |
| 404 | 1 | 43.0 | 27.7208 | 0 | 1 |
| 405 | 2 | 20.0 | 13.8625 | 0 | 1 |
| 406 | 2 | 23.0 | 10.5000 | 0 | 1 |
| 407 | 1 | 50.0 | 211.5000 | 0 | 1 |
| 408 | 3 | 28.0 | 7.7208 | 1 | 0 |
| 409 | 3 | 3.0 | 13.7750 | 1 | 0 |
| 410 | 3 | 28.0 | 7.7500 | 1 | 0 |
| 411 | 1 | 37.0 | 90.0000 | 1 | 0 |
| 412 | 3 | 28.0 | 7.7750 | 1 | 0 |
| 413 | 3 | 28.0 | 8.0500 | 0 | 1 |
| 414 | 1 | 39.0 | 108.9000 | 1 | 0 |
| 415 | 3 | 38.5 | 7.2500 | 0 | 1 |
| 416 | 3 | 28.0 | 8.0500 | 0 | 1 |
| 417 | 3 | 28.0 | 22.3583 | 0 | 1 |
1309 rows × 5 columns
In [32]:
train, test = all_df[:train_df.shape[0]], all_df[train_df.shape[0]:]
train.shape, test.shape
Out[32]:
((891, 5), (418, 5))
In [33]:
t_train = train_df["Survived"].values
x_train = train.values
x_test = test.values
scikit-learn¶

決定木で予測¶
In [34]:
import sklearn.tree
clf_decision_tree = sklearn.tree.DecisionTreeClassifier(max_depth=2, random_state=0)
In [35]:
clf_decision_tree.fit(x_train, t_train)
Out[35]:
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=0,
splitter='best')
In [36]:
y_train = clf_decision_tree.predict(x_train)
y_train
Out[36]:
array([0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1,
0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0,
1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0,
1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0,
1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0,
0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0,
0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0,
1, 0, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0,
1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0,
0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,
0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0,
0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0,
0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0,
1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1,
0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1,
0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1,
0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0,
1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0])
accuracy(正解数÷データ数)はライブラリを使うまでもないですが
In [37]:
sum(t_train == y_train) / len(t_train)
Out[37]:
0.79573512906846244
In [38]:
sklearn.metrics.accuracy_score(t_train, y_train)
Out[38]:
0.79573512906846244
長いimportはこれで短縮(名前空間を汚染するので諸刃の剣)
In [39]:
from sklearn.metrics import accuracy_score
accuracy_score(t_train, y_train)
Out[39]:
0.79573512906846244
クラス数が多い分類はconfusion matrixを見ると傾向がつかみやすい
In [40]:
from sklearn.metrics import confusion_matrix
confusion_matrix(t_train, y_train)
Out[40]:
array([[532, 17],
[165, 177]])
In [41]:
from sklearn.metrics import classification_report
print(classification_report(t_train, y_train))
precision recall f1-score support
0 0.76 0.97 0.85 549
1 0.91 0.52 0.66 342
avg / total 0.82 0.80 0.78 891
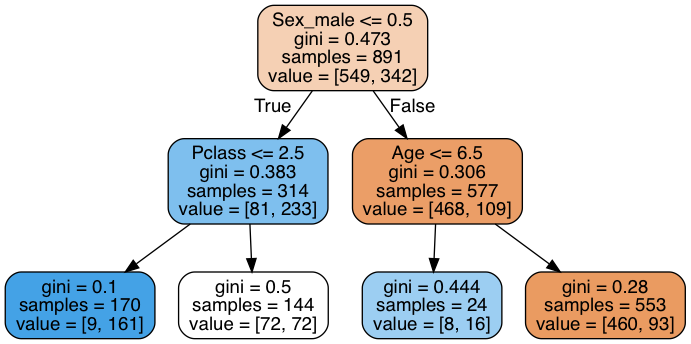
決定木の可視化¶
graphvizを別途インストールしていないと動きません^^;
In [42]:
import pydotplus
from sklearn.externals.six import StringIO
dot_data = StringIO()
sklearn.tree.export_graphviz(clf_decision_tree, out_file=dot_data
, feature_names=train.columns, filled=True, rounded=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
# PDFファイルに出力
# graph.write_pdf("graph.pdf")
In [43]:
from IPython.display import Image
Image(graph.create_png())
Out[43]:
Random Forestで予測¶
In [44]:
from sklearn.ensemble import RandomForestClassifier
# n_estimatorは木の数
clf_random_forest = RandomForestClassifier(n_estimators=100, random_state=0)
In [45]:
clf_random_forest.fit(x_train, t_train)
Out[45]:
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=1,
oob_score=False, random_state=0, verbose=0, warm_start=False)
In [46]:
y_train = clf_random_forest.predict(x_train)
print(accuracy_score(t_train, y_train))
0.977553310887
In [47]:
print(classification_report(t_train, y_train))
precision recall f1-score support
0 0.98 0.99 0.98 549
1 0.98 0.96 0.97 342
avg / total 0.98 0.98 0.98 891
In [48]:
print(confusion_matrix(t_train, y_train))
[[541 8]
[ 12 330]]
3.予測モデルの評価¶
モデルを良くする¶
- もっといいパラメータがあるのでは?パラメータをいろいろ試す必要がある.→ Grid Search
- 他のデータでもうまく行く保証はあるのか?過学習(overfitting) を防ぎたい=汎化性能を高める.→ Cross Varidation

両方skit-learnでできます!
In [49]:
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
tuned_parameters = [
{'C': [1, 1e1, 1e2, 1e3, 1e4],
'kernel': ['rbf'],
'gamma': [1e-2, 1e-3, 1e-4]},
]
clf_SVC_cv = GridSearchCV(
SVC(random_state=0),
tuned_parameters,
cv=5,
scoring="f1",
n_jobs=-1
)
In [50]:
clf_SVC_cv.fit(x_train, t_train)
Out[50]:
GridSearchCV(cv=5, error_score='raise',
estimator=SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=0, shrinking=True,
tol=0.001, verbose=False),
fit_params=None, iid=True, n_jobs=-1,
param_grid=[{'C': [1, 10.0, 100.0, 1000.0, 10000.0], 'kernel': ['rbf'], 'gamma': [0.01, 0.001, 0.0001]}],
pre_dispatch='2*n_jobs', refit=True, return_train_score=True,
scoring='f1', verbose=0)
In [51]:
pd.DataFrame(clf_SVC_cv.cv_results_)
Out[51]:
| mean_fit_time | mean_score_time | mean_test_score | mean_train_score | param_C | param_gamma | param_kernel | params | rank_test_score | split0_test_score | ... | split2_test_score | split2_train_score | split3_test_score | split3_train_score | split4_test_score | split4_train_score | std_fit_time | std_score_time | std_test_score | std_train_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.022302 | 0.004612 | 0.500432 | 0.599439 | 1 | 0.01 | rbf | {'C': 1, 'gamma': 0.01, 'kernel': 'rbf'} | 12 | 0.348624 | ... | 0.537037 | 0.581395 | 0.469388 | 0.593103 | 0.596491 | 0.565321 | 0.000882 | 0.000682 | 0.086323 | 0.025639 |
| 1 | 0.017771 | 0.003363 | 0.478282 | 0.498602 | 1 | 0.001 | rbf | {'C': 1, 'gamma': 0.001, 'kernel': 'rbf'} | 13 | 0.336283 | ... | 0.509434 | 0.513636 | 0.437500 | 0.432836 | 0.563636 | 0.494172 | 0.000585 | 0.000074 | 0.083251 | 0.041543 |
| 2 | 0.015337 | 0.003225 | 0.373277 | 0.401322 | 1 | 0.0001 | rbf | {'C': 1, 'gamma': 0.0001, 'kernel': 'rbf'} | 15 | 0.222222 | ... | 0.333333 | 0.368000 | 0.391304 | 0.354839 | 0.391304 | 0.381963 | 0.000719 | 0.000057 | 0.099299 | 0.047146 |
| 3 | 0.030071 | 0.002918 | 0.680114 | 0.808045 | 10 | 0.01 | rbf | {'C': 10.0, 'gamma': 0.01, 'kernel': 'rbf'} | 9 | 0.666667 | ... | 0.676471 | 0.802239 | 0.638655 | 0.797794 | 0.733813 | 0.791128 | 0.003710 | 0.000044 | 0.030994 | 0.014921 |
| 4 | 0.023025 | 0.003189 | 0.696823 | 0.736891 | 10 | 0.001 | rbf | {'C': 10.0, 'gamma': 0.001, 'kernel': 'rbf'} | 7 | 0.671053 | ... | 0.705036 | 0.739526 | 0.651163 | 0.758123 | 0.706767 | 0.719858 | 0.002123 | 0.000111 | 0.033928 | 0.012797 |
| 5 | 0.016498 | 0.003338 | 0.442728 | 0.442583 | 10 | 0.0001 | rbf | {'C': 10.0, 'gamma': 0.0001, 'kernel': 'rbf'} | 14 | 0.330275 | ... | 0.421053 | 0.422680 | 0.458333 | 0.390501 | 0.453608 | 0.416452 | 0.001508 | 0.000120 | 0.070980 | 0.047659 |
| 6 | 0.115308 | 0.002867 | 0.685099 | 0.851002 | 100 | 0.01 | rbf | {'C': 100.0, 'gamma': 0.01, 'kernel': 'rbf'} | 8 | 0.652778 | ... | 0.724638 | 0.851449 | 0.656000 | 0.843066 | 0.725926 | 0.845173 | 0.029387 | 0.000320 | 0.033026 | 0.006237 |
| 7 | 0.049189 | 0.002460 | 0.710631 | 0.771008 | 100 | 0.001 | rbf | {'C': 100.0, 'gamma': 0.001, 'kernel': 'rbf'} | 5 | 0.701987 | ... | 0.724638 | 0.763158 | 0.645161 | 0.772313 | 0.755556 | 0.753731 | 0.009958 | 0.000300 | 0.036865 | 0.012765 |
| 8 | 0.041163 | 0.003029 | 0.704471 | 0.713795 | 100 | 0.0001 | rbf | {'C': 100.0, 'gamma': 0.0001, 'kernel': 'rbf'} | 6 | 0.733813 | ... | 0.695652 | 0.719101 | 0.625000 | 0.724584 | 0.723077 | 0.711111 | 0.012930 | 0.000138 | 0.042910 | 0.007052 |
| 9 | 0.572957 | 0.002542 | 0.669756 | 0.870491 | 1000 | 0.01 | rbf | {'C': 1000.0, 'gamma': 0.01, 'kernel': 'rbf'} | 10 | 0.652778 | ... | 0.704225 | 0.862816 | 0.638655 | 0.866667 | 0.696296 | 0.871324 | 0.242091 | 0.000094 | 0.025698 | 0.005719 |
| 10 | 0.311519 | 0.002486 | 0.715629 | 0.794218 | 1000 | 0.001 | rbf | {'C': 1000.0, 'gamma': 0.001, 'kernel': 'rbf'} | 2 | 0.716216 | ... | 0.716418 | 0.785441 | 0.672131 | 0.788104 | 0.779412 | 0.780037 | 0.082325 | 0.000140 | 0.035728 | 0.013975 |
| 11 | 0.174307 | 0.003853 | 0.712710 | 0.722426 | 1000 | 0.0001 | rbf | {'C': 1000.0, 'gamma': 0.0001, 'kernel': 'rbf'} | 4 | 0.739130 | ... | 0.705882 | 0.722117 | 0.645161 | 0.738806 | 0.723077 | 0.716981 | 0.075424 | 0.002672 | 0.036903 | 0.008729 |
| 12 | 4.124018 | 0.001604 | 0.649124 | 0.888971 | 10000 | 0.01 | rbf | {'C': 10000.0, 'gamma': 0.01, 'kernel': 'rbf'} | 11 | 0.638298 | ... | 0.686567 | 0.881481 | 0.611570 | 0.890130 | 0.656489 | 0.887218 | 1.239600 | 0.000048 | 0.024471 | 0.004438 |
| 13 | 1.460751 | 0.001553 | 0.713517 | 0.814629 | 10000 | 0.001 | rbf | {'C': 10000.0, 'gamma': 0.001, 'kernel': 'rbf'} | 3 | 0.722222 | ... | 0.729927 | 0.798479 | 0.650407 | 0.811111 | 0.770370 | 0.812386 | 0.218736 | 0.000039 | 0.039692 | 0.010188 |
| 14 | 0.505528 | 0.002130 | 0.724973 | 0.755406 | 10000 | 0.0001 | rbf | {'C': 10000.0, 'gamma': 0.0001, 'kernel': 'rbf'} | 1 | 0.753425 | ... | 0.720588 | 0.756554 | 0.650407 | 0.769797 | 0.753846 | 0.726930 | 0.216026 | 0.000431 | 0.039189 | 0.015732 |
15 rows × 23 columns
In [52]:
clf_SVC_cv.best_params_
Out[52]:
{'C': 10000.0, 'gamma': 0.0001, 'kernel': 'rbf'}
In [53]:
clf_SVC_cv.best_score_
Out[53]:
0.72497257558382566
In [54]:
y_train = clf_SVC_cv.predict(x_train)
print(classification_report(t_train, y_train))
precision recall f1-score support
0 0.84 0.87 0.85 549
1 0.77 0.73 0.75 342
avg / total 0.81 0.82 0.81 891
In [55]:
print(accuracy_score(t_train, y_train))
0.81593714927
In [56]:
print(confusion_matrix(t_train, y_train))
[[476 73]
[ 91 251]]
モデルの保存¶
In [57]:
from sklearn.externals import joblib
joblib.dump(clf_SVC_cv.best_estimator_, 'svc.pkl.cmp', compress=True)
Out[57]:
['svc.pkl.cmp']
In [58]:
!ls
Python01.ipynb _templates predict_result.csv
Python02.ipynb conf.py siritori.pkl
_static index.rst svc.pkl.cmp
In [59]:
classifier = joblib.load('svc.pkl.cmp')
In [60]:
y_train = clf_SVC_cv.predict(x_train)
print(accuracy_score(t_train, y_train))
0.81593714927
Kaggleへテストの結果を提出¶
問題分を読んで回答に合う形式で提出
In [61]:
y_test = clf_SVC_cv.predict(x_test)
In [62]:
result_df = pd.DataFrame({
"PassengerId": test.index,
"Survived": y_test
})
result_df
Out[62]:
| PassengerId | Survived | |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 2 | 0 |
| 3 | 3 | 0 |
| 4 | 4 | 1 |
| 5 | 5 | 0 |
| 6 | 6 | 1 |
| 7 | 7 | 0 |
| 8 | 8 | 1 |
| 9 | 9 | 0 |
| 10 | 10 | 0 |
| 11 | 11 | 0 |
| 12 | 12 | 1 |
| 13 | 13 | 0 |
| 14 | 14 | 1 |
| 15 | 15 | 1 |
| 16 | 16 | 0 |
| 17 | 17 | 0 |
| 18 | 18 | 1 |
| 19 | 19 | 1 |
| 20 | 20 | 0 |
| 21 | 21 | 0 |
| 22 | 22 | 1 |
| 23 | 23 | 0 |
| 24 | 24 | 1 |
| 25 | 25 | 0 |
| 26 | 26 | 1 |
| 27 | 27 | 0 |
| 28 | 28 | 0 |
| 29 | 29 | 0 |
| ... | ... | ... |
| 388 | 388 | 0 |
| 389 | 389 | 0 |
| 390 | 390 | 0 |
| 391 | 391 | 1 |
| 392 | 392 | 0 |
| 393 | 393 | 0 |
| 394 | 394 | 0 |
| 395 | 395 | 1 |
| 396 | 396 | 0 |
| 397 | 397 | 1 |
| 398 | 398 | 0 |
| 399 | 399 | 0 |
| 400 | 400 | 1 |
| 401 | 401 | 0 |
| 402 | 402 | 1 |
| 403 | 403 | 0 |
| 404 | 404 | 0 |
| 405 | 405 | 0 |
| 406 | 406 | 0 |
| 407 | 407 | 0 |
| 408 | 408 | 1 |
| 409 | 409 | 1 |
| 410 | 410 | 1 |
| 411 | 411 | 1 |
| 412 | 412 | 1 |
| 413 | 413 | 0 |
| 414 | 414 | 1 |
| 415 | 415 | 0 |
| 416 | 416 | 0 |
| 417 | 417 | 0 |
418 rows × 2 columns
In [63]:
result_df.to_csv('predict_result.csv', index=False)
In [64]:
!head predict_result.csv
PassengerId,Survived
0,0
1,1
2,0
3,0
4,1
5,0
6,1
7,0
8,1
おわりに¶
ノーフリーランチ定理¶

醜いアヒルの子の定理¶

見せかけの回帰¶

テキサスの狙撃兵の誤謬(クラスター錯覚)¶

ハンマー釘病¶
If all you have is a hammer, Everything looks like a nail. 